
Demo of Synthetic Control Method (a Replication)
Published:
In this post, I have two objectives. First, I am going to walk through a basic demonstration of the synthetic control method. Second, I am going to report a simple replication of the basic results in a recently published paper, in the Proceedings of the National Academy of Sciences:
- Mitze, T., Kosfeld, R., Rode, J., & Wälde, K. (2020). Face masks considerably reduce COVID-19 cases in Germany. Proceedings of the National Academy of Sciences, 117(51), 32293-32301.
Note: all replication materials are posted in this GitHub repository.
Some Intuition for Synth Control
The Synthetic Control Method (SCM for short) was introduced by Abadie, Diamond and Hainmueller, in a 2010 paper that was published in JASA. I’ll first provide some basic intuition for the method, before I get into the application.
As a researcher (or more commonly, as a policy analyst), we sometimes encounter situations in which we have 1 (or very few) treated panels, and the available control panels are not immediately useful. The treated panel is just ‘too different’. This might be apparent, for example, from an inspection of pre-trends in the outcome variable.
If all of the available control panels are too different, matching can’t resolve this. A related, alternative approach would be re-weighting (e.g., IPW). This, essentially, is what SCM implements. It identifies a linear, weighted combination that maps control unit outcomes to outcomes in the treated unit, when the treatment is not active (i.e., in the pre-treatment period).
What is this exercise really doing then? We can think about this “mapping” exercise as a prediction problem (note: viewed this way, we might think of difference-in-differences as an inflexible approach to capturing / representing the mapping between treatment and control panels, i.e., it’s a shitty prediction algorithm, and a parallel trend violation amounts to prediction error). What SCM does is allow for greater flexibility in the mapping between treatment and control. It accomplishes this by allowing for a fractional representation of individual panels when it learns the mapping, via re-weighting.
Assuming we can learn how to use the control panels’ outcomes to predict the treatment panel outcome before treatment turns on, we can apply that learned prediction into the post period, to speculate about what would have happened to the treated panel had the treatment never turned on. Of course, there are some nuances here that I am glossing over. For example, the weights we learn under SCM are constrained to be non-negative, selected controls need to lie in the convex hull of the treated panel, i.e., control panels cannot be ‘too different’ from the treated panel. As I’ve stated previously, I encourage you to go read the original paper, as well as subsequent innovations, e.g., synthetic difference in differences, generalized synthetic control and synthetic control using LASSO, or SCUL.
I am going to provide a quick demonstration of the SCM, via a replication of some recently published work in PNAS. At the same time, I’ll demonstrate SCM using LASSO as well, given the number of available controls is quite large in this case.
Replicating Mitze et al (2020, PNAS)
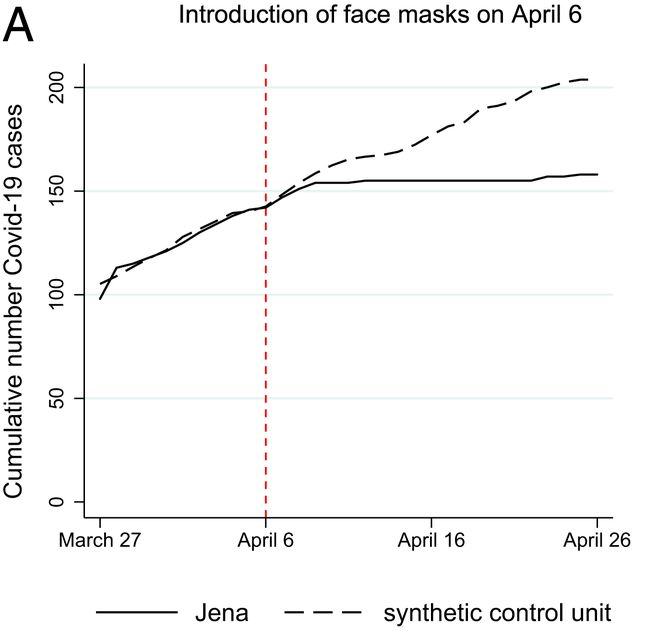
Mitze et al. (2020, PNAS) examine a case study in Germany around the mandatory imposition of face masks in Jena, Germany, on April 6th of 2020. They employed this policy event as a natural experiment, to estimate the effect of mandatory face mask policies on COVID-19 case rates. Interestingly, this setup is also something of an ideal use case for SCM; we have a single treated location (the unit of analysis here is a district), and many controls (hundreds of other, untreated districts, in fact). Below is the main result of the study, a figure, which depicts the actual cumulative covid case series in Jena (solid line), and the estimated synthetic counterfactual (dashed line). This is the result we are going to try to reproduce.
Data / Measures
Now, I originally sought to replicate this study because I needed a teaching example for my graduate-level causal inference course. The study seemed like a wonderful candidate for replication, because PNAS requires authors to disclose data and analysis scripts as supplementary appendices. Unfortunately, in this case, I was unable to locate anything approximating useful replication materials. The supplementary appendix did not include any analysis scripts (despite the authors’ claim to the contrary in their paper), and the data that were provided amounted to a single spreadsheet, with a handful of time series (certainly not the entirety of raw data that were used to construct a synthetic control). Rather than give up, I decided to locate the datasets the authors had claimed to have used in their study. After some digging, I was able to locate most of the relevant data.
Data on daily COVID-19 case reports for each German district and day have been published by the Robert Koch Institute since January of 2020. They have been made available publicly, via API. Fortunately, someone has been collecting that data and sharing it on a GitHub repository! See here.
I was then able to locate data for most of the control covariates the authors mentioned in their paper, by scouring different German Census Data portals (not a fun exercise when you cannot speak German!). I located data on the number of physicians per capita in each district, number of pharmacies, number of hospital beds, as well as data on resident volumes by age category, gender and so on.
Many, if not most of the covariates are available from DEStatis, including population counts by age range, as well as by gender. Further, data on a region’s local healthcare infrastructure, including physicians per capita, hospital beds, and number of pharmacies are available on an annual basis in the INKAR database, maintained by the German Federal Institute for Research on Building, Urban Affairs and Spatial Development (be prepared to use Google Translate if you don’t speak German!). I obtained the most recently available published values for each district, but I want to note that, using SCUL, which is more flexible than standard SCM, we will not need these additional covariates to do a good job.)
Data Import & Integration
I am going to import and integrate the COVID-19 daily cumulative case volumes, district names (for labels / interpretation), and a few of the district characteristics: physicians per capita, pharmacy volumes, and count of individuals by age range. I will ultimately use the latter in my SCM implementation to arrive at a result that looks rather similar to that published in the paper. However, using SCUL, as you will see, we can do a good job without those features.
Let’s import and integrate the data…
library(tidyr)
library(broom)
library(dplyr)
library(ggplot2)
library(glmnet) # I'm going to use this for LASSO to select control panels.
library(janitor) # I will use this to clear some missing values.
library(Synth) # This is the original SCM package implemented by Diamond.
library(ggthemes)
library(patchwork)
library(tmap)
### Let's import Covid-19 case volume data from german districts, by day..
setwd("/Users/gburtch/Google Drive/Teaching/Courses/MSBA 6440/2021/(9) Synthetic Control /Covid-19 Facemasks/")
covid <- read.csv("Covid_DE_cases_by_district.csv")
dist_names <- read.csv("Covid_DE_district_IDs.csv")
covid <- covid %>% merge(dist_names, by.x = "dist_id", by.y = "id")
# Let's convert date column into date format.
covid$date <- as.Date(covid$date)
covid <- covid[order(covid$dist_id,covid$date),]
# We can pull in other features, though these are not actually required.
# E.g., we can pull in physicians per capita in each district.
setwd("/Users/gburtch/Google Drive/Teaching/Courses/MSBA 6440/2021/(9) Synthetic Control /Covid-19 Facemasks/district_demographics/")
dist_physicians <- read.csv("dist_phys_pcap.csv",sep=";") %>% rename("dist_id" = "Kennziffer", "physicians" = "Ärzte.je..Einwohner") %>% filter(!is.na(dist_id)) %>% select(c(dist_id,physicians))
dist_physicians$physicians <- as.numeric(gsub(",",".",dist_physicians$physicians))
covid <- covid %>% merge(dist_physicians, by="dist_id", all.x=TRUE)
# We now pull in pharmacy information.
dist_pharma <- read.csv("dist_pharmas_2017.csv",sep=";") %>% filter(!is.na(Kennziffer)) %>% rename("dist_id" = "Kennziffer","pharmacies" = "Apotheken")
dist_pharma$pharmacies <- as.numeric(gsub(",",".",dist_pharma$pharmacies))
dist_pharma <- dist_pharma %>% select(c(dist_id,pharmacies))
covid <- covid %>% merge(dist_pharma, by="dist_id",all.x=TRUE)
# We can pull in population information by age, and so on now as well.
dist_pop <- read.csv("dist_pop_age.csv", sep=";") %>% select(-c(dist_name))
dist_pop$year <- substr(dist_pop$year,1,4)
# Some missing values here.
dist_pop <- dist_pop %>% lapply(as.integer) %>% as.data.frame()
# We have yearly values for 3 years - let's just use the most recent set of values in 2019.
dist_pop <- dist_pop %>% filter(year==2019) %>% select(-c(year))
covid <- covid %>% merge(dist_pop, by="dist_id", all.x=TRUE)
# Jena is district id 16053.
covid$treat <- covid$dist_id==16053
# Let's trim to a reasonable window around the event date.
covid <- subset(covid, date > as.numeric(as.Date("2020-03-01")) & date <= as.numeric(as.Date("2020-05-21")))
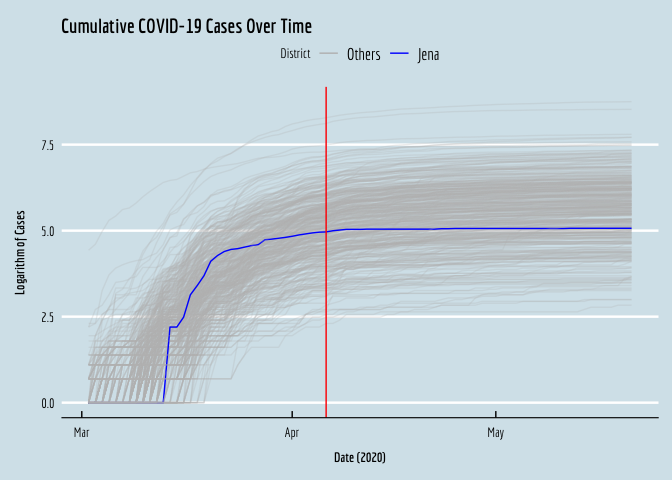
Now that we’ve imported and integrated the data, we can visualize the cumulative COVID case series for all the districts, to see what was going on in early 2020. I’m going to plot the log of each series. Note that the case volumes are very right-skewed, so if we plot the levels over time we have a very hard time seeing what was going on in most of the (smaller) districts, as the big districts expand the range of the y-axis and compress the small locations together at the bottom of the plot.
# Hard to see much here in the descriptive plot of the time series.
# Jena is there at the bottom, though hard to see.
ggplot(data=covid,aes(x=date,y=log(cum_cases+1),color=factor(treat),group=dist_id,alpha=treat)) +
geom_line() +
geom_vline(xintercept=as.numeric(as.Date("2020-04-06")),color="red") +
xlab(expression(bold(paste("Date (2020)")))) +
ylab(expression(bold(paste("Logarithm of Cases")))) +
scale_alpha_manual(guide=FALSE,values=c(0.25,1))+
scale_color_manual(name="District",labels=c("Others", "Jena"),values=c("gray","blue"))+
ggtitle("Cumulative COVID-19 Cases Over Time") +
theme_economist() +
#Comment the below line out if you don't have Economica fonts installed.
theme(text = element_text(family = "Economica", size = 10), axis.title.y = element_text(margin = margin(t = 0, r = 10, b = 0, l = 0)),axis.title.x = element_text(margin = margin(t = 10, r = 0, b = 0, l = 0)))+
NULL
We can see the treated district, Jena, in blue, right in the middle.
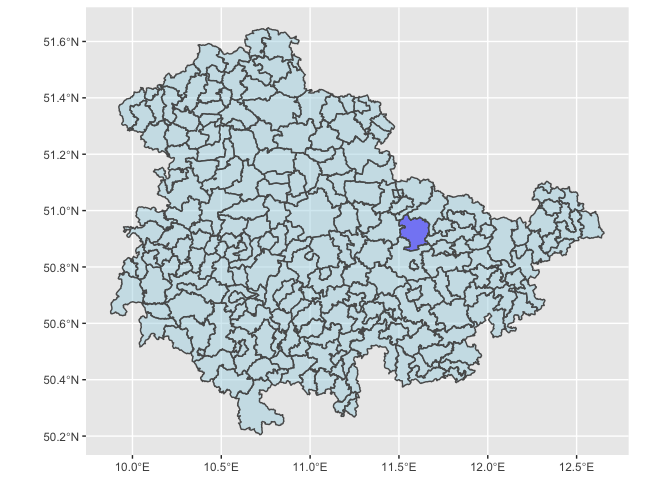
We can also visualize these locations, so we have a sense of where Jena is, and its spatial neighbors, which we may ultimately be worried about excluding, to avoid SUTVA violations.
# We can quickly plot where Jena is located within its state in Germany.
DE_Districts <- readRDS(url("https://biogeo.ucdavis.edu/data/gadm3.6/Rsf/gadm36_DEU_3_sf.rds"))
DE_Districts$isJena <- ifelse(DE_Districts$NAME_2=="Jena", "blue", "lightblue")
ggplot(data=DE_Districts %>% filter(NAME_1=="Thüringen")) + geom_sf(aes(fill = isJena),alpha=0.5) + scale_fill_manual(guide=FALSE,values=c("blue","lightblue"))
Synthetic Control Using LASSO (SCUL)
I’m going to start off implementing a synthetic control estimate employing a cross-validated LASSO to identify the best set of control districts and their associated weights that minimize prediction error for the treated panel’s covid numbers in the pre-treatment period. After I do this, I’ll pivot to the traditional SCM using the Synth package (hold tight).
The first thing we need to do is to pivot the panel from long format to wide format. This is because we need the control panels’ covid case time series to appear as columns (features) that can be used to predict the time series in Jena.
# I'm demonstrating syntax here for the pivot_wider function. After I transform the data like this, observations are uniquely identified by the date variable (rather than district-date).
covid.wide <- covid %>% pivot_wider(id_cols=c("date"),names_from=c("district"),values_from=c("cum_cases","under.3.years","yr.3.to.under.6.years"))
# I'm also going to then pull out pre-treatment observations, which we will use to 'train' the model that will yield the synthetic control for Jena.
covid.wide.train <- subset(covid.wide,date<as.numeric(as.Date("2020-04-06")))
Now, I’m going to use a 5-fold cross validated LASSO to identify the control district time series that are ‘useful’ for predicting the treatment outcome. LASSO is useful here because we have something of a curse of dimensionality problem. This is because we have ~400 predictors, but just 35 observations!
# We have many more predictors than time periods now, so we let's do some feature selection.
# I'm going ot use LASSO to pick the controls I'll work with.
covid.wide.train.lasso <- remove_empty(covid.wide.train, which=c("rows","cols"))
covid.wide.train_mm <- model.matrix(`cum_cases_ SK Jena`~.,covid.wide.train.lasso)
lasso <- cv.glmnet(covid.wide.train_mm, covid.wide.train$`cum_cases_ SK Jena`, standardize=TRUE,alpha=1,nfolds=5)
ests <- as.matrix(coef(lasso,lasso$lambda.1se))
# Here are the non-zero control panels that lasso selected.
names(ests[ests!=0,])
## [1] "(Intercept)" "`cum_cases_ LK Lüchow-Dannenberg`"
## [3] "`cum_cases_ LK Warendorf`" "`cum_cases_ LK Alzey-Worms`"
## [5] "`cum_cases_ LK Oder-Spree`"
Of course, we could run predictions right off the resulting LASSO model, but I’m going to just quickly use the selected controls in a simple linear model to generate these predictions (it’s faster / easier syntax wise).
# Okay, let's build our 'synthetic control'.
fml.rhs <- paste(c(names(ests[ests!=0,]))[2:length(names(ests[ests!=0,]))],collapse="+")
fml <- as.formula(paste("`cum_cases_ SK Jena`~",fml.rhs))
synth <- lm(data=covid.wide.train,formula=fml)
# Now we can synthesize the control series in the original data, into the post period.
covid.wide$synth <- predict(synth,newdata = covid.wide)
# Now we can visualize the result.
OLS_plot <- ggplot(data=covid.wide,aes(y=synth,x=date,linetype="dashed")) + geom_line() +
geom_line(aes(y=`cum_cases_ SK Jena`,x=date,linetype="solid")) +
geom_vline(xintercept=as.numeric(as.Date("2020-04-06")),color="red") +
xlab(expression(bold(paste("Date (2020)")))) +
ylab(expression(bold(paste("Cumulative COVID-19 Cases")))) +
scale_linetype_manual(name="Series",values=c("dashed","solid"),labels=c("Synth","Jena, DE"))+
ggtitle("Effect of Masks on COVID-19 (LASSO -> OLS Synth)") +
theme_economist() +
#Comment the below line out if you don't have Economica fonts installed.
theme(text = element_text(family = "Economica", size = 10), axis.title.y = element_text(margin = margin(t = 0, r = 10, b = 0, l = 0)),axis.title.x = element_text(margin = margin(t = 10, r = 0, b = 0, l = 0)))+
xlim(as.Date("2020-03-27"),as.Date("2020-04-26")) +
ylim(0,225)+
NULL
# Let's see how we did.
OLS_plot
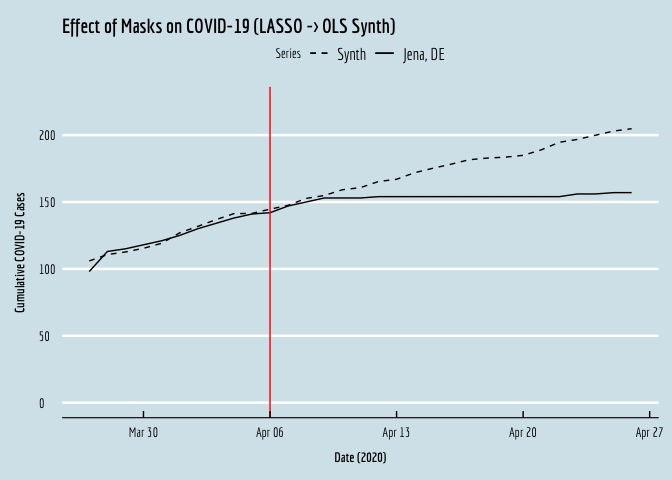
If we compare the resulting plot against the original from the manuscript, we see that the two are virtually identical! Okay, let’s do this again, using the Synth package.
Vanilla Synthetic Control
With the Synth package, we don’t need to manually pivot the data and implement the prediction step. Instead, we employ the provided data preparation function, Synth::dataprep(). There are a few things we need to do here for the Synth package to run; it seems the outcome variable name creates problems, so we rename it to `Y’. We also need to provide a numeric date variable.
# That was quick and dirty, so let's do this properly now.
# We can implement SCM properly using the Synth package.
# This package will implement appropriate non-negativity constraints on the control weights.
# This package will also minimize MSPE (whereas a simple OLS minimizes SSE)
# The outcome variable renamed to Y as Synth isn't liking the original variable name.
covid <- covid %>% rename(Y = cum_cases)
# Let's also eliminate missing values.
covid <- subset(covid,complete.cases(covid))
# Synth requires numeric date and unit ID variables.
covid$date2 <- as.numeric(covid$date)
# Synth requires a list of control ID's - let's pull them out here.
# Note: 16053 is Jena.
# The authors also omitted a few neighboring districts, and districts that instituted their own mask policies soon after Jena.
# We thus also exclude 16071; Weimarer Land, 16062; Nordhausen, and 8325; Rottweil.
# The authors also omitted Saale-Holzland, but we lose it due to missing data on district features anyway.
dist_ids <- unique(covid$dist_id)
control_ids <- dist_ids[dist_ids != 16053 & dist_ids != 16071 & dist_ids != 16062 & dist_ids != 8325]
# Now we use Synth's data preparation package.
dataprep.out=
dataprep(foo = covid,
dependent = "Y",
unit.variable = "dist_id",
time.variable = "date2",
# The authors used a lot of seemingly irrelevant predictors
# For example, average female age? Average male age? Why is gender important?
# I am going to keep things simple here: pharmacies, physicians and elderly.
predictors = c("pharmacies","physicians","yr.75.years.and.over"),
predictors.op = "mean",
# We can also predict using case volumes day before treatment and week before treatment.
special.predictors = list(list("Y", 18356, "mean"),list("Y", 18350, "mean")),
#which panel is treated?
treatment.identifier = 16053,
#which panels are we using to construct the synthetic control?
# Controls here will be every other district.
controls.identifier = control_ids,
#what is the pre-treatment time period?
#these numeric values correspond to 34 days before treatment.
#the paper only uses the 14 days before treatment for some reason?
time.predictors.prior = c(18323:18357),
time.optimize.ssr = c(18323:18357),
#name of panel units
unit.names.variable = "district",
#time period to generate the plot for.
#paper only goes 20 days post treatment because other treatments started.
#We will just see what this looks like, however.
time.plot = 18343:18403)
# Note that this will take a few minutes to run.
synth.out = synth(dataprep.out)
##
## X1, X0, Z1, Z0 all come directly from dataprep object.
##
##
## ****************
## searching for synthetic control unit
##
##
## ****************
## ****************
## ****************
##
## MSPE (LOSS V): 472.0547
##
## solution.v:
## 0.0529831 0.001509989 0.005108959 0.415707 0.5246909
##
## solution.w:
## 0.006564324 0.0004055885 0.002139966 0.0005085972 0.0004717398 0.0001726535 0.001062503 0.0003717301 0.0001553077 0.0006183037 0.0003629104 0.0004292388 0.000214448 0.0005860168 0.0002270336 2.79219e-05 0.0002271632 0.000628013 0.0004829527 0.000390823 0.0002124507 0.0004434707 0.0005673657 0.0002652501 0.0003682191 0.0001827385 0.0001242331 0.0002416202 0.0002879616 0.0005218277 0.0003477228 0.0004412265 0.0003997039 0.0004270034 0.0007675313 0.000144265 0.001345292 0.0003719313 0.001306577 0.0007560607 0.0004403459 0.000663049 0.0003067929 0.001126626 0.05237426 0.0003507623 0.0005205719 0.0008072831 0.0005942938 0.0004740093 0.000620547 0.0003305482 0.0005693599 0.0003246393 0.0004914106 0.0003196319 0.0001490839 0.0002105214 0.00180959 0.00115103 0.0002978122 0.002039214 0.0001240423 0.0002045301 0.001574565 0.0002616505 0.0002325824 0.0003221188 0.0002445388 0.0004001476 0.0004201843 0.0001471107 0.0004923532 0.000188074 0.0001523593 0.0004416121 0.0002053172 0.0001631632 0.0003219535 9.58203e-05 0.000234878 0.0002050765 0.06544548 0.0004305961 0.0001964088 0.001757817 0.0001405515 0.0003435191 0.0001139985 0.0001188078 0.002006019 0.0003078525 0.001077941 0.0002023739 0.0001605391 0.0002187687 0.0002118577 0.0001120851 0.0005017758 0.0001682759 0.0004192505 0.0002007967 0.0009861359 0.000207707 0.0002424023 0.0005260073 0.0001512545 0.0005050657 0.0001253503 0.001209401 0.000357899 0.0002991036 0.0002980169 0.0004344054 0.0002979694 0.0004105386 0.0005220736 0.0005506335 0.0009082208 0.0002931952 0.0001741712 0.0004410594 0.0003583363 0.001469201 0.0006399747 0.0009927966 0.000267859 0.0005731917 0.001610907 0.0007549825 0.0007665145 0.0005780913 0.0005685147 0.000346942 0.0004736354 0.0007802962 0.000480617 0.0002575291 0.0002197481 0.0004033966 0.0005396109 0.01702708 0.0006910843 0.0002728648 0.0004891146 0.0009247413 0.0004451911 0.0003947985 0.0012924 0.0006579095 0.0003279909 0.0002251532 0.0003035838 0.0006816194 0.0001100815 0.000110077 0.0001957902 8.92393e-05 0.000161345 0.0003177445 0.0001173775 0.0001525583 0.0001868206 0.0003078109 9.68291e-05 0.0004031858 0.0004374914 0.0003373717 0.0002773775 0.0002698433 0.0002364188 0.000133005 9.85326e-05 0.0001511048 0.0001293801 0.0001198902 0.0001279613 0.0001923618 7.40931e-05 0.0002496367 0.0003414894 0.0001834988 0.0009165521 0.0001394759 0.0001281896 4.3254e-06 0.0002836983 0.0001253415 0.000200505 0.0001666862 0.0001124552 0.0001868573 0.0002221662 0.0002759306 0.0001302242 0.0001187129 0.0002096688 0.0002030344 0.0002388523 0.0001376266 0.0001015472 0.0003670412 0.0001559687 6.56068e-05 0.0002574874 9.62221e-05 0.0002260809 0.0002909219 0.0001239602 0.0001139023 0.0008568023 0.0008437727 0.0001246845 0.000159693 0.0001179923 0.000247116 0.0001071825 0.0001161343 0.0004820284 4.244e-07 0.0001889062 1.127e-07 0.0001614196 0.000234749 0.0002434387 9.18673e-05 0.0001718004 0.0001230177 7.74223e-05 0.0001725594 0.0001950936 1.2617e-06 0.0001457934 0.000180458 0.0002065278 0.0004320233 0.0002392633 0.0001771677 0.000711023 0.0003375406 0.0002776858 9.96867e-05 7.72069e-05 0.0002154276 0.0001955858 9.43256e-05 0.0008514579 0.0001518622 0.0002032977 0.0001075794 0.000104161 0.0003480851 0.000156387 0.0002204248 0.0001045169 3.20147e-05 0.000328717 0.0001293496 0.0002312601 0.000312998 0.0003495092 0.000322791 0.0002070512 0.0003287026 0.0001711766 0.0002519045 0.0003092016 0.0001423332 0.0003898202 6.67261e-05 0.0002612041 0.0002425694 0.0002583305 0.0003137275 0.000161908 0.0002678846 0.0001149333 0.0002722593 0.0001508385 0.0005065323 7.58301e-05 0.000201842 0.0002509582 0.0001001168 0.0003467085 4.703e-07 0.219204 0.05040197 0.0001100537 0.0003030347 0.0002735372 0.0004007101 0.0002149661 0.000498744 0.0003815238 0.0006121857 0.1031712 0.0004561474 0.0001271576 0.0009067293 2.2528e-06 0.0003776801 0.0004829234 0.008468471 0.002414929 0.000341158 0.0004588724 0.0003994225 0.0003864519 0.0004557052 0.0005491755 0.0003457466 0.0002201051 0.000166056 0.0002779092 0.0006580341 0.0001340395 0.0002304415 0.0001902925 0.000209378 0.0003712971 0.0002737388 0.0006609773 0.0002704255 0.001077984 0.0006974887 0.0005978265 0.0003584995 0.0006985959 0.0004581608 0.001427668 0.0004159547 0.00164145 0.0004776158 0.3425815 0.0006896883 0.000220863 0.0007110676 0.001627077 0.0005692535 0.001382997 0.001282586 0.0003697402 0.0005982611 0.0003684731 0.0008136127
We can then use the native plotting functions from Synth to visualize the result, as follows. These plots rely on the base plotting tools in R. The result is essentially the same, except that now we get a weaker treatment effect. I should note here that when I omitted the additional predictor covariates in my first pass at this, and the resulting synthetic control looked quite poor in the pre period. I then explored the inclusion of additional covariate predictors in something of a trial-and-error manner to arrive at this result.
# Path.plot() plots the synthetic against the actual treated unit data.
path.plot(dataprep.res = dataprep.out, synth.res = synth.out,Xlab="Date",Ylab="Cumulative COVID-19 Cases",Main="Comparison of Synth vs. Actual Cum. COVID-19 Cases in Jena, Germany")
# And we can add a vertical line where the treatment occurred.
abline(v=18358,lty=2,col="red")
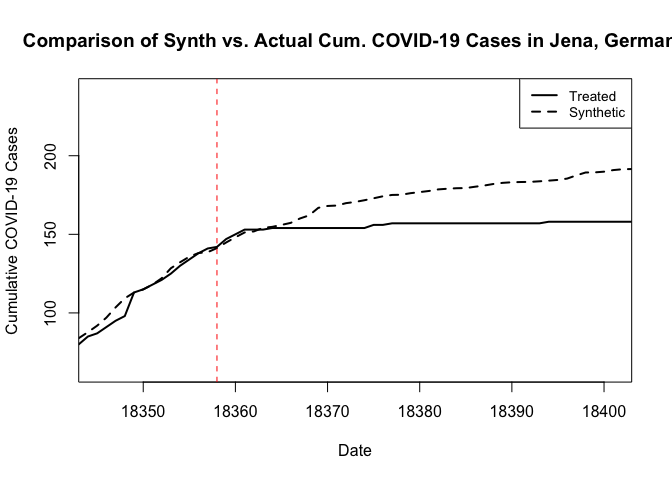
Alternatively, we can pull out the results and generate our own, prettier plots, as follows.
# Let's pull out the data from the result, to make our own nicer plots in ggplot of course
synth_data_out = data.frame(dataprep.out$Y0plot%*%synth.out$solution.w)
date = as.numeric(row.names(synth_data_out))
plot.df = data.frame(y=covid$Y[covid$dist_id==16053 & covid$date2 %in% date])
plot.df$synth = synth_data_out$w.weight
plot.df$date <- covid$date[covid$dist_id==16053 & covid$date2 %in% date]
SCM_plot <- ggplot(plot.df,aes(y=y,x=date,linetype="solid")) + geom_line() +
geom_line(aes(y=synth,x=date,linetype="dashed")) +
geom_vline(xintercept=18358,color="red") +
xlab(expression(bold(paste("Date (2020)")))) +
ylab(expression(bold(paste("Cumulative COVID-19 Cases")))) +
scale_linetype_manual(name="Series",values=c("dashed","solid"),labels=c("Synth","Jena, DE"))+
ggtitle("Effect of Masks on COVID-19 (Proper Synth)") +
theme_economist() +
#Comment the below line out if you don't have Economica fonts installed.
theme(text = element_text(family = "Economica", size = 10), axis.title.y = element_text(margin = margin(t = 0, r = 10, b = 0, l = 0)),axis.title.x = element_text(margin = margin(t = 10, r = 0, b = 0, l = 0)))+
ylim(0,225)+
NULL
# Let's put the two plots side-by-side.
SCM_plot
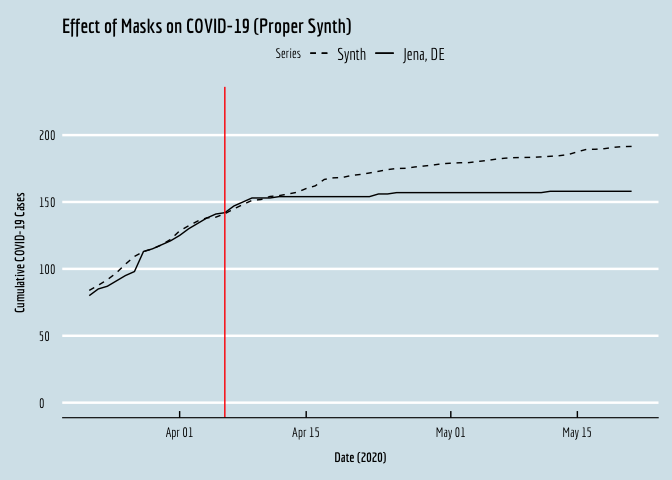
… et voila!